#java remove duplicates
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
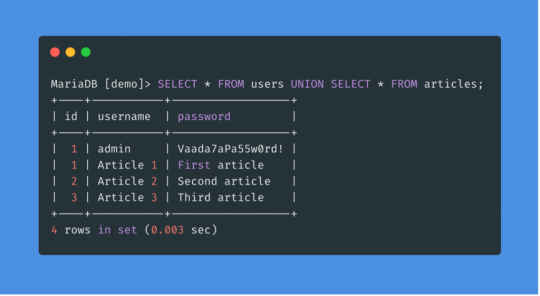
Text
SQLi Potential Mitigation Measures
Phase: Architecture and Design
Strategy: Libraries or Frameworks
Use a vetted library or framework that prevents this weakness or makes it easier to avoid. For example, persistence layers like Hibernate or Enterprise Java Beans can offer protection against SQL injection when used correctly.
Phase: Architecture and Design
Strategy: Parameterization
Use structured mechanisms that enforce separation between data and code, such as prepared statements, parameterized queries, or stored procedures. Avoid constructing and executing query strings with "exec" to prevent SQL injection [REF-867].
Phases: Architecture and Design; Operation
Strategy: Environment Hardening
Run your code with the minimum privileges necessary for the task [REF-76]. Limit user privileges to prevent unauthorized access if an attack occurs, such as by ensuring database applications don’t run as an administrator.
Phase: Architecture and Design
Duplicate client-side security checks on the server to avoid CWE-602. Attackers can bypass client checks by altering values or removing checks entirely, making server-side validation essential.
Phase: Implementation
Strategy: Output Encoding
Avoid dynamically generating query strings, code, or commands that mix control and data. If unavoidable, use strict allowlists, escape/filter characters, and quote arguments to mitigate risks like SQL injection (CWE-88).
Phase: Implementation
Strategy: Input Validation
Assume all input is malicious. Use strict input validation with allowlists for specifications and reject non-conforming inputs. For SQL queries, limit characters based on parameter expectations for attack prevention.
Phase: Architecture and Design
Strategy: Enforcement by Conversion
For limited sets of acceptable inputs, map fixed values like numeric IDs to filenames or URLs, rejecting anything outside the known set.
Phase: Implementation
Ensure error messages reveal only necessary details, avoiding cryptic language or excessive information. Store sensitive error details in logs but be cautious with content visible to users to prevent revealing internal states.
Phase: Operation
Strategy: Firewall
Use an application firewall to detect attacks against weaknesses in cases where the code can’t be fixed. Firewalls offer defense in depth, though they may require customization and won’t cover all input vectors.
Phases: Operation; Implementation
Strategy: Environment Hardening
In PHP, avoid using register_globals to prevent weaknesses like CWE-95 and CWE-621. Avoid emulating this feature to reduce risks. source
3 notes
·
View notes
Text
Sweep AI: The Future of Automated Code Refactoring
Introduction to Sweep AI
In today’s digital age, writing and maintaining clean code can wear developers down. Deadlines pile up, bugs pop in, and projects often fall behind. That’s where Sweep AI steps in. It acts as a reliable coding assistant that saves time, boosts productivity, and supports developers by doing the heavy lifting in coding tasks.
This article breaks down everything about Sweep AI, how it helps with code automation, and why many developers choose it as their go-to AI tool.
Understanding Sweep AI
Sweep AI is an open-source AI-powered tool that behaves like a junior developer. It listens to your needs, reads your code, and writes or fixes it accordingly. It can turn bug reports into actual code fixes without needing constant manual guidance.
More importantly, Sweep AI does not cost a dime to start. It’s ideal for teams and solo developers who want to move fast without sacrificing code quality.
How Sweep AI Works
Sweep AI works in a simple yet powerful way. Once a developer writes a feature request or a bug report, the AI jumps into action. Here’s what it usually does:
Reads the existing code
Plans the changes intelligently
Writes pull requests automatically
Updates based on comments or suggestions
Sweep AI also uses popularity ranking to understand which parts of your repository matter the most. It responds to feedback and works closely with developers throughout the code improvement process.
Types of Refactoring Sweeps AI Can Handle
Sweeps AI does not just work on surface-level improvements. It digs deep into the code. Some of its main capabilities include:
Function extraction: breaking large functions into smaller, clearer ones
Renaming variables: making names more meaningful
Removing dead code: getting rid of unused blocks
Code formatting: applying consistent style and spacing
It can also detect complex issues like duplicate logic across files, risky design patterns, and nested loops that slow down performance.
Why Developers Are Turning to Sweeps AI
Many developers use Sweeps AI because it:
Saves time
Reduces human error
Maintains consistent coding standards
Improves software quality
Imagine a junior developer who must refactor 500 lines of spaghetti code. That person might take hours or even days to clean it up. With Sweeps AI, the job could be done in minutes.
Step-by-Step Guide to Start Using Sweep AI
You don’t need to be a tech wizard to get started with Sweep AI. Here are two easy methods:
Install the Sweep AI GitHub App Connects to your repository and starts working almost immediately.
Self-host using Docker Ideal for developers who want more control or need to run it privately.
Sweep AI also shares helpful guides, video tutorials, and documentation to walk users through each step.
The Present and the Future
Right now, Sweeps AI already supports languages like Python, JavaScript, TypeScript, and Java. But the roadmap includes support for C++, PHP, and even legacy languages like COBOL. That shows just how ambitious the project is.
In the coming years, we might see Sweeps AI integrated into platforms like GitHub, VS Code, and JetBrains IDES by default. That means you won’t need to go out of your way to use it will be part of your everyday coding workflow.
How Much Does Sweep AI Cost?
Sweep AI offers a flexible pricing model:
Free Tier – Unlimited GPT-3.5 tickets for all users.
Plus Plan – $120/month includes 30 GPT-4 tickets for more advanced tasks.
GPT-4 Access – Requires users to connect their own Openai API key (charges may apply).
Whether you’re working on a startup project or a large codebase, there’s a plan that fits.
Is Sweep AI Worth It?
Absolutely. Sweep AI is more than just another coding assistant it’s a valuable teammate. It understands what you need, helps you fix problems faster, and lets you focus on what really matters: building great products.
Thanks to its smart features and developer-friendly design, Sweep AI stands out as one of the top AI tools for modern software teams. So, if you haven’t tried it yet, now’s a good time to dive in and take advantage of what it offers.
Frequently Asked Questions
Q: Who is the founder of Sweep AI?
Sweep AI was co-founded by William Suryawan and Kevin Luo, two AI engineers focused on making AI useful for developers by automating common tasks in GitHub.
Q: Is there another AI like Chatgpt?
Yes, there are several AIS similar to Chatgpt, including Claude, Gemini (by Google), Cohere, and Anthropic’s Claude. However, Sweep AI is more focused on code generation and GitHub integrations.
Q: Which AI solves GitHub issues?
Sweep AI is one of the top tools for automatically solving GitHub issues by generating pull requests based on bug reports or feature requests. It acts like a junior developer who understands your project.
Q: What is an AI agent, and how does it work?
An AI agent is a software program that performs tasks autonomously using artificial intelligence. It receives input (like code requests), makes decisions, and performs actions (like fixing bugs or writing code) based on logic and data.
Q: Who is the CEO of Sweep.io?
As of the latest information, Kevin Luo serves as the CEO of Sweep.io, focusing on making AI development tools smarter and more accessible.
0 notes
Text
Must-Know Core Java Concepts for Every Programmer
(A Guide for Full Stack Software Testing Enthusiasts in KPHB)
Java remains the backbone of enterprise applications, and a strong grasp of its core concepts is essential for every programmer. Whether you are an aspiring software tester, a backend developer, or a full-stack engineer, understanding Java fundamentals is non-negotiable. Let’s break down the most crucial Java concepts that you must master.

1. Object-Oriented Programming (OOP)
Java is inherently object-oriented, which means everything revolves around objects and classes. The four key pillars of OOP in Java are:
✔ Encapsulation – Bundling data and methods together to protect data integrity. ✔ Abstraction – Hiding implementation details and exposing only what’s necessary. ✔ Inheritance – Allowing one class to derive properties from another. ✔ Polymorphism – Enabling multiple implementations of a method.
Why It Matters?
For software testers, understanding OOP principles helps in creating reusable and scalable test automation frameworks.
2. Java Memory Management
Memory management is a crucial aspect that determines the performance of Java applications. It consists of:
✔ Heap & Stack Memory – Heap stores objects, while Stack holds method calls and local variables. ✔ Garbage Collection (GC) – Java has an automatic garbage collector that frees up memory by removing unused objects.
Why It Matters?
Full Stack Testers must understand memory leaks and performance bottlenecks in Java-based applications.
3. Exception Handling
Exception handling ensures that runtime errors don’t crash the application. Java provides:
✔ try-catch-finally – Handles exceptions and ensures resource cleanup. ✔ throws & throw – Used for explicitly handling custom exceptions. ✔ Checked vs. Unchecked Exceptions – Checked exceptions (like IOException) must be handled, while unchecked exceptions (like NullPointerException) occur at runtime.
Why It Matters?
Testers need to handle exceptions effectively in automation scripts to avoid script failures.
4. Multithreading & Concurrency
Multithreading allows multiple parts of a program to run simultaneously. Important concepts include:
✔ Thread Lifecycle – From creation to termination. ✔ Runnable & Callable Interfaces – Implementing threads in Java. ✔ Synchronization & Locks – Avoiding race conditions and ensuring thread safety.
Why It Matters?
In performance testing, understanding multithreading helps simulate real-world user load.
5. Collections Framework
Java provides a robust Collections Framework for handling groups of objects efficiently. The key interfaces are:
✔ List (ArrayList, LinkedList) – Ordered and allows duplicates. ✔ Set (HashSet, TreeSet) – Unordered and doesn’t allow duplicates. ✔ Map (HashMap, TreeMap) – Stores key-value pairs.
Why It Matters?
Test automation frameworks use collections extensively for data handling and assertions.
6. File Handling & I/O Operations
File handling is critical for reading, writing, and manipulating files in Java.
✔ BufferedReader & BufferedWriter – Efficient file reading and writing. ✔ FileInputStream & FileOutputStream – Handling binary data. ✔ Serialization – Converting objects into byte streams.
Why It Matters?
For automation testers, handling logs, reports, and configuration files is a routine task.
7. JDBC & Database Connectivity
Java Database Connectivity (JDBC) allows applications to interact with databases.
✔ DriverManager – Manages database connections. ✔ PreparedStatement – Prevents SQL injection. ✔ ResultSet – Retrieves query results.
Why It Matters?
Full Stack Testers should understand JDBC for validating database operations in automation scripts.
8. Java Frameworks
Mastering Java alone isn’t enough; knowing key frameworks is essential.
✔ Spring Boot – Microservices and dependency injection. ✔ Selenium with Java – Web automation testing. ✔ TestNG & JUnit – Test automation frameworks.
Why It Matters?
These frameworks power large-scale software applications and automation testing.
Frequently Asked Questions (FAQ)
Q1: What is the best way to practice Core Java concepts? A: Work on small projects, participate in coding challenges, and contribute to open-source repositories.
Q2: How is Java used in Full Stack Software Testing? A: Java is used for writing test automation scripts, interacting with databases, and integrating test frameworks.
Q3: What is the difference between Checked and Unchecked Exceptions? A: Checked exceptions must be handled (e.g., IOException), whereas unchecked exceptions occur at runtime (e.g., NullPointerException).
Q4: Why is Java preferred for automation testing? A: Java offers robust libraries like Selenium, TestNG, and JUnit, making automation testing efficient and scalable.
Q5: What are the key Java concepts needed for API Testing? A: Understanding HTTP methods, JSON parsing, and REST API calls using libraries like RestAssured and Jackson is crucial.
Final Thoughts
Mastering Java fundamentals is the key to excelling in software development and automation testing. Whether you are preparing for a Full Stack Software Testing role in KPHB or looking to enhance your coding skills, these core Java concepts will set you apart.
#Java#CoreJava#FullStackTesting#SoftwareTesting#AutomationTesting#JavaProgramming#Selenium#TestAutomation#OOP#Coding#JavaDeveloper#JUnit#TestNG#FullStackDevelopment#KPHB#TechLearning
0 notes
Text
Exploring Java Streams API for Functional Programming
Exploring Java Streams API for Functional Programming
The Java Streams API, introduced in Java 8, provides a functional approach to processing collections of data. It allows developers to write concise, readable, and efficient code using declarative programming rather than imperative loops.
1. What is the Java Streams API?
A Stream in Java is a sequence of elements that supports various functional operations such as filtering, mapping, and reducing. It enables a lazy evaluation approach, meaning elements are processed only when needed.
Key Features: ✔ Supports functional programming concepts. ✔ Works with Collections, Arrays, and I/O sources. ✔ Uses internal iteration, improving performance. ✔ Supports parallel processing for efficiency.
2. Creating a Stream
A stream can be created from collections, arrays, or other data sources.
Example 1: Creating a Stream from a List
import java.util.List; import java.util.stream.Stream;public class StreamExample { public static void main(String[] args) { List<String> names = List.of("Alice", "Bob", "Charlie"); Stream<String> nameStream = names.stream(); nameStream.forEach(System.out::println); } }
Example 2: Creating a Stream from an Arra
import java.util.Arrays; import java.util.stream.Stream;public class ArrayStreamExample { public static void main(String[] args) { String[] arr = {"Java", "Python", "C++"}; Stream<String> stream = Arrays.stream(arr); stream.forEach(System.out::println); } }
3. Stream Operations
Java Streams API provides various methods for functional-style programming.
Intermediate Operations (Return another Stream)
OperationDescriptionfilter(Predicate<T>)Filters elements based on a conditionmap(Function<T,R>)Transforms each elementsorted()Sorts elements in natural orderdistinct()Removes duplicate elementslimit(n)Limits the number of elements
Terminal Operations (End the Stream)
OperationDescriptioncollect(Collectors.toList())Collects elements into a listforEach(Consumer<T>)Iterates over elementsreduce(BinaryOperator<T>)Reduces elements to a single valuecount()Returns the number of elementsanyMatch(Predicate<T>)Checks if any element matches a condition
4. Functional Programming with Streams
Example 1: Filtering a List
import java.util.List; import java.util.stream.Collectors;public class FilterExample { public static void main(String[] args) { List<String> names = List.of("Alice", "Bob", "Charlie", "Amanda"); List<String> filteredNames = names.stream() .filter(name -> name.startsWith("A")) .collect(Collectors.toList()); System.out.println(filteredNames); // Output: [Alice, Amanda] } }
Example 2: Mapping Elements
import java.util.List; import java.util.stream.Collectors;public class MapExample { public static void main(String[] args) { List<String> names = List.of("alice", "bob", "charlie"); List<String> upperCaseNames = names.stream() .map(String::toUpperCase) .collect(Collectors.toList()); System.out.println(upperCaseNames); // Output: [ALICE, BOB, CHARLIE] } }
Example 3: Reducing Elements
import java.util.List;public class ReduceExample { public static void main(String[] args) { List<Integer> numbers = List.of(1, 2, 3, 4, 5); int sum = numbers.stream().reduce(0, Integer::sum); System.out.println("Sum: " + sum); // Output: Sum: 15 } }
5. Parallel Streams for Performance
Java Streams API supports parallel execution to improve performance.import java.util.List;public class ParallelStreamExample { public static void main(String[] args) { List<Integer> numbers = List.of(1, 2, 3, 4, 5); int sum = numbers.parallelStream().reduce(0, Integer::sum); System.out.println("Sum: " + sum); } }
Parallel streams can speed up processing for large datasets by using multi-core processors.
6. When to Use Streams API?
✔ When you need to process large datasets efficiently. ✔ When functional programming improves readability and conciseness. ✔ When you want to leverage parallel processing for performance gains.
⚠ Avoid Streams when: ❌ The operation is very simple (e.g., a single loop is sufficient). ❌ The operation modifies the underlying collection.
Conclusion
The Java Streams API enables developers to write clean, declarative, and functional-style code. By using operations like filter, map, reduce, and parallel processing, we can handle complex data transformations efficiently.
WEBSITE: https://www.ficusoft.in/core-java-training-in-chennai/
0 notes
Text
hi
Longest Substring Without Repeating Characters Problem: Find the length of the longest substring without repeating characters. Link: Longest Substring Without Repeating Characters
Median of Two Sorted Arrays Problem: Find the median of two sorted arrays. Link: Median of Two Sorted Arrays
Longest Palindromic Substring Problem: Find the longest palindromic substring in a given string. Link: Longest Palindromic Substring
Zigzag Conversion Problem: Convert a string to a zigzag pattern on a given number of rows. Link: Zigzag Conversion
Three Sum LeetCode #15: Find all unique triplets in the array which gives the sum of zero.
Container With Most Water LeetCode #11: Find two lines that together with the x-axis form a container that holds the most water.
Longest Substring Without Repeating Characters LeetCode #3: Find the length of the longest substring without repeating characters.
Product of Array Except Self LeetCode #238: Return an array such that each element is the product of all the other elements.
Valid Anagram LeetCode #242: Determine if two strings are anagrams.
Linked Lists Reverse Linked List LeetCode #206: Reverse a singly linked list.
Merge Two Sorted Lists LeetCode #21: Merge two sorted linked lists into a single sorted linked list.
Linked List Cycle LeetCode #141: Detect if a linked list has a cycle in it.
Remove Nth Node From End of List LeetCode #19: Remove the nth node from the end of a linked list.
Palindrome Linked List LeetCode #234: Check if a linked list is a palindrome.
Trees and Graphs Binary Tree Inorder Traversal LeetCode #94: Perform an inorder traversal of a binary tree.
Lowest Common Ancestor of a Binary Search Tree LeetCode #235: Find the lowest common ancestor of two nodes in a BST.
Binary Tree Level Order Traversal LeetCode #102: Traverse a binary tree level by level.
Validate Binary Search Tree LeetCode #98: Check if a binary tree is a valid BST.
Symmetric Tree LeetCode #101: Determine if a tree is symmetric.
Dynamic Programming Climbing Stairs LeetCode #70: Count the number of ways to reach the top of a staircase.
Longest Increasing Subsequence LeetCode #300: Find the length of the longest increasing subsequence.
Coin Change LeetCode #322: Given a set of coins, find the minimum number of coins to make a given amount.
Maximum Subarray LeetCode #53: Find the contiguous subarray with the maximum sum.
House Robber LeetCode #198: Maximize the amount of money you can rob without robbing two adjacent houses.
Collections and Hashing Group Anagrams LeetCode #49: Group anagrams together using Java Collections.
Top K Frequent Elements LeetCode #347: Find the k most frequent elements in an array.
Intersection of Two Arrays II LeetCode #350: Find the intersection of two arrays, allowing for duplicates.
LRU Cache LeetCode #146: Implement a Least Recently Used (LRU) cache.
Valid Parentheses LeetCode #20: Check if a string of parentheses is valid using a stack.
Sorting and Searching Merge Intervals LeetCode #56: Merge overlapping intervals.
Search in Rotated Sorted Array LeetCode #33: Search for a target value in a rotated sorted array.
Kth Largest Element in an Array LeetCode #215: Find the kth largest element in an array.
Median of Two Sorted Arrays LeetCode #4: Find the median of two sorted arrays.
0 notes
Text
Java Map: A Comprehensive Overview

The Java Map interface is a crucial part of the Java Collections Framework, providing a structure for storing key-value pairs. Among its popular implementations is the HashMap, which offers efficient performance for basic operations like insertion and retrieval by using a hash table.
For developers looking to dive deeper into this topic, resources such as JAVATPOINT offer comprehensive guides and tutorials on HashMap and other map implementations.
Understanding how to use HashMap and other Java Map types can significantly enhance your ability to manage and access data effectively in your Java applications.
Basic Concepts
A Map does not allow duplicate keys; each key can map to only one value. If you insert a new value for an existing key, the old value is overwritten. The primary operations that Map provides include adding entries, removing entries, and retrieving values based on keys. It also supports checking if a key or value is present and getting the size of the map.
Key Implementations
Several classes implement the Map interface, each with its own characteristics:
HashMap: This is the most commonly used Map implementation. It uses a hash table to store the key-value pairs, which provides average constant-time performance for basic operations such as get and put. However, HashMap does not guarantee the order of its entries. It is ideal for scenarios where performance is critical, and the order of elements is not important.
LinkedHashMap: This implementation extends HashMap and maintains a linked list of entries to preserve the insertion order. This means that when iterating over the entries of a LinkedHashMap, they will appear in the order they were inserted. This implementation is useful when you need predictable iteration order and can afford a slight performance trade-off compared to HashMap.
TreeMap: A TreeMap is a sorted map that uses a Red-Black tree to store its entries. It sorts the keys in their natural order or according to a specified comparator. This implementation is suitable when you need a map that maintains sorted order and supports range views. However, it has a higher overhead compared to HashMap and LinkedHashMap due to the tree-based structure.
Common Operations
The Map interface provides a variety of methods to interact with the data:
put(K key, V value): Adds a key-value pair to the map. If the key already exists, it updates the value.
get(Object key): Retrieves the value associated with the specified key. Returns null if the key does not exist.
remove(Object key): Removes the key-value pair associated with the specified key.
containsKey(Object key): Checks if the map contains the specified key.
containsValue(Object value): Checks if the map contains the specified value.
keySet(): Returns a set view of the keys contained in the map.
values(): Returns a collection view of the values contained in the map.
entrySet(): Returns a set view of the key-value pairs (entries) contained in the map.
Use Cases
Map implementations are versatile and can be used in a variety of scenarios:
Caching: Store frequently accessed data for quick retrieval.
Counting: Track the occurrence of elements or events.
Lookup Tables: Create efficient lookup tables for quick access to data.
Conclusion
Understanding the Map interface and its implementations is essential for effective Java programming. The HashMap is a popular choice for its efficiency in handling key-value pairs with average constant-time performance, making it ideal for various applications.
For those interested in delving deeper into data structures and their uses, resources like TpointTech offer valuable insights and tutorials on concepts such as the hashmap java.
Mastery of these tools allows developers to write more efficient and effective code, leveraging the strengths of each Map implementation to meet their specific needs.
0 notes
Text
Deleting Duplicates in a Singly Linked List: A Java Solution
82. Remove Duplicates from Sorted List II Given the head of a sorted linked list, delete all nodes that have duplicate numbers, leaving only distinct numbers from the original list. Return the linked list sorted as well. Example 1: Input: head = [1,2,3,3,4,4,5] Output: [1,2,5] Example 2: Input: head = [1,1,1,2,3] Output: [2,3] Constraints: The number of nodes in the list is in the range…

View On WordPress
0 notes
Text
Leveraging Kotlin Collections in Android Development
Kotlin has gradually replaced Java as the lingua franca of Android programming. It’s a more concise language than Java, meaning your code works harder and you can build leaner applications. And Kotlin Collections are fundamental.
These collections play a fundamental role in our work as programmers by simplifying the organization and management of data. Whether it’s a list, set, map or other data structure, they allow us to categorize and store data logically. So we can save, retrieve and manipulate information, and manage a range of tasks from simple data presentation to complex algorithm implementation.
Collections also facilitate code reusability, enabling us to utilize their existing functions and methods rather than developing individual data-handling mechanisms for every task This streamlines development, reduces errors and enhances code maintainability.
At a granular level, collections enable us to perform operations like sorting, filtering, and aggregation efficiently, improving the overall quality of our products.
Overview of Kotlin Collections
Kotlin Collections come in three primary forms: Lists, Maps, and Sets. Each is a distinct type, with its unique characteristics and use cases. Here they are:
Kotlin Lists
A Kotlin List is a sequential arrangement of elements that permit duplicate values, preserving the order in which they are added.
Elements in a list are accessed by their index, and you can have multiple elements with the same value.
Lists are a great help when storing a collection of items whose order needs to be maintained – for example, a to-do list – and storing duplicate values.
Kotlin Maps
Kotlin Maps are collections of key-value pairs. In lightweight markdown language, a method allows us to link values with distinct keys, facilitating effortless retrieval of values using their corresponding keys.
The keys are also ideal for efficient data retrieval and mapping relationships between entities.
Common use cases of Kotlin Maps include building dictionaries, storing settings, and representing relationships between objects.
Kotlin Set
A Kotlin Set is an unordered collection of distinct elements, meaning it does not allow duplicate values.
Sets are useful when you need to maintain a unique set of elements and do not require a specific order for those elements.
Common use cases of Kotlin Sets include tracking unique items, such as unique user IDs, or filtering out duplicates from a list.
The choice between lists, maps, and sets depends on your specific data requirements. Lists are suitable for ordered collections with potential duplicates, maps are ideal for key-value associations, and sets are perfect for maintaining unique, unordered elements.
Kotlin Immutable vs Mutable Collections
Kotlin provides support for both immutable and mutable collections, giving you flexibility when managing data.
Immutable Collections
Immutable collections cannot be modified once they are created. They provide both general safety and specific thread safety, making them ideal for scenarios where you want to keep the data constant. Immutable collections are created using functions like listOf() , mapOf() , and setOf() .
Mutable Collections
A mutable collection can be modified after creation. These collections are more flexible and versatile, allowing you to add, remove or modify individual elements. Mutable collections are created using functions like mutableListOf() , mutableMapOf(), and mutableSetOf().
Now that we have a foundational understanding of Kotlin collections, let’s dive deeper into each type.
Using Kotlin List
How to create a list in Kotlin
Creating a Kotlin list is straightforward. Here are two great ways to get started.
Create an immutable list
To create an immutable list we can use listOf(). Check out the following example:// Example Of listOf function fun main(args: Array<String>) { //initialize list var listA = listOf<String>("Anupam", "Singh", "Developer") //accessing elements using square brackets println(listA[0]) //accessing elements using get() println(listA.get(2)) }
In the Kotlin console, you will see the following output:[Anupam, native, android, developer]
Create a mutable list
If you want to create a mutable list, we should use the mutableListOf() method. Here is an example:// Example of mutableListOf function fun main(args: Array<String>) { //initialize a mutable list var listA = mutableListOf("Anupam", "Is", "Native") //add item to the list listA.add("Developer") //print the list println(listA) }
And this is the output :[Anupam, Is, Native, Developer]
Working with a Kotlin List
Now, we’ll look at working with list items.
Accessing elements from the List
We can reach a list item using its place or index. Here’s the first item from the cantChangeList.// get first item from list var cantChangeList = listOf<Int>(1, 2, 3) val firstItem = cantChangeList[0] println(firstItem) //Output: 1
Iterating over a list
There are multiple ways to traverse a list effectively, leveraging higher-order functions such as *forEach* or utilizing for loops. This enables you to handle the list’s elements one after the other, in sequence. For example:var MyList = listOf<Int>(1, 2, 3) // print each item from list using for loop for (element in myList) { println(element) } //output: //1 //2 //3 // print each item from list using forEach loop MyList.forEach { println(it) } // Output: // 1 // 2 // 3
Adding elements from a list
Modifying a Kotlin List is a great option for mutable lists that harness functions like *add()* , **remove()** , and set(). If we want to add an element to a list, we will simply use the add()method.// Example of add() function in list val numberAdd = mutableListOf(1, 2, 3, 4) numberAdd.add(5) println(numberAdd) //Output : [1, 2, 3, 4, 5]
Removing elements from a list
Removing elements is also a straightforward process. Here’s a coding example:// Example of remove() function in list val numberRemove = mutableListOf(1, 2, 3, 4) numberRemove.remove(3) println(numberRemove) //Output: [1, 2, 4]
Modifying List Items
Altering list items is simple. You can swap them directly with new data via their indices or by using the set commands. Here we have an example of changing an item value, either through its place marker or by using the setmethod:var myList = mutableListOf<String>("Anupam","five", "test", "change") // Changing value via index access myList[0] = "FreshValue" println(myList[0]) // Ouput: // FreshValue // Changing value using set method myList.set(0, "SetValue") println(myList[0]) // Ouput: // SetValue
Other list functions and operations
In Kotlin, list methods are essential tools when we work with collections. While there are numerous methods available, we’ll limit our focus to the most commonly used ones today.
Each of these methods brings its own unique power and utility to a Kotlin collection. Now let’s explore them in detail.
sorted() : Returns a new List with elements sorted in natural order.
sortedDescending() : Returns a new List with elements sorted in descending order.
filter() : Returns a new List containing elements that satisfy a given condition.
map() : Transforms each element of the List, based on a given predicate.
isEmpty() : Checks whether the List is empty.
Here are some key examples of these methods:
Sort a Kotlin list
This collection includes the following elements (3, 1, 7, 2, 8, 6).
Here they are in ascending order:// Ascending Sort val numbs = mutableListOf(3, 1, 7, 2, 8, 6) println(numbs) val sortedNumbs = numbs.sorted() println(sortedNumbs) //Output: // Before Sort : [3, 1, 7, 2, 8, 6] // After Sort : [1, 2, 3, 6, 7, 8]
Now, here’s an example of sorting in descending order:// Descending Sort val numbs = mutableListOf(3, 1, 7, 2, 8, 6) println(numbs) val sortedDesNumbs = numbs.sortedDescending() println(sortedDesNumbs) //Output: // Before Sort : [3, 1, 7, 2, 8, 6] // After Sort : [8, 7, 6, 3, 2, 1]
Filtering a Kotlin list
If you want to filter a Kotlin list, you can use the filter function. This allows you to specify a condition that each element of the list must satisfy in order to be included in the filtered list. Here’s an example:val listOfData = listOf("Anupam","is","native","android","developer") val longerThan5 = listOfData.filter { it.length > 5 } println(longerThan5)
In this example, we have a list of strings under the heading listOfData. We use the filter function to create a new list, longerThan5 , that contains only the strings from listOfData with a length greater than five characters.
Finally, we print the filtered list. The output will be:[Anupam, native, android, developer]
Check whether a Kotlin list is empty
Here you can use the isEmpty() function, as you can see in this example:val myList = listOf<Int>() if (myList.isEmpty()) { println("The list is empty.") } else { println("The list is not empty.") } // Output: // The list is empty.
In the following example we’ll create a list, myList , with values using the listOf() function, so the isEmpty will return false:// example of isEmpty() return false var list = listOf<String>("Anupam") if (list.isEmpty()) { println("Its empty.") } else { println("Its not empty.") } // Output: // Its not empty.
Transforming a list using map
As we mentioned earlier, the Kotlin map function is a powerful tool for transforming each element of a list into a new form. It applies a specified transformation function to each element and returns a new list with the results. This gives us a concise way to modify the elements in a list, without mutating the original collection.val numbers = listOf(1, 2, 3, 4, 5) val squaredNumbers = numbers.map { it * it } println(squaredNumbers) // Output: // [1, 4, 9, 16, 25]
In this example, we have a list called numbers, containing integers. We apply the map function to numbers and provide a lambda expression as the transformation function. The lambda expression takes each element in the numbers list and returns its square. The map function applies this transformation to each element of the list and creates a new list, squaredNumbers, with the squared values.
Searching elements in a List
Check whether element exists in the list
To search for an element in a Kotlin list, you can utilize the various methods available in the Kotlin standard library. One widely used method is the contains() function, which allows you to check whether a list contains a specific element.
Here’s an example of how you can use the contains() function in Kotlin:val myList = listOf("apple", "banana", "orange") val isElementFound = myList.contains("banana") if (isElementFound) { println("Element found!") } else { println("Element not found!") } // Output: // banana
You can also use the filter() method we mentioned earlier to filter all the elements that match a given criteria.
Search the element and get its index
Another option is to use the indexOf() method, which returns the specific position of an element in the list.val myList = listOf("apple", "banana", "orange") val index = myList.indexOf("banana") if (index != -1) { println("Element found at index $index") } else { println("Element not found in the list") } // Output: // Element found at index 1
Working with Kotlin Map
Accessing and modifying a Kotlin Map
Creating and initializing a map in Kotlin
In Kotlin, you can create and initialize a map by utilizing either the mapOf() function for immutable maps or the mutableMapOf() function for mutable maps. Here is an example of how you can create a map containing names and ages:// Immutable Map Example. Syntax is mapOf<key,value> val myImmuMap = mapOf<Int,String>(1 to "Anupam", 2 to "Singh", 3 to "Developer") for(key in myImmuMap.keys){ println(myImmuMap[key]) } // Output : // Anupam // Singh // Developer
The mapOf() function allows you to create an immutable map, ensuring that its content cannot be altered once initialized. Conversely, the **mutableMapOf()** function enables you to modify the map, transforming it into a mutable map.
In the example provided, the map contains pairs of names and ages. Each pair is created using the ‘to’ keyword, where the name is associated with its corresponding age. The map’s content is enclosed in curly brackets which look like {}.
By utilizing these functions, you can easily create and initialize maps in Kotlin according to your specific needs.
Retrieving map values
To access values in a Map, you use the associated key. For example, to get the value of “Anupam” in ‘immutable map’, you can do the:val myImmuMap = mapOf<Int,String>(1 to "Anupam", 2 to "Singh", 3 to "Developer") val valueOfAnupam = myImmuMap["Anupam"] // valueOfAnupam will be 1
Modify a map entry
You can also modify the values in a mutable Map, using keys:val myImmuMap = mapOf<Int,String>(1 to "Anupam", 2 to "Singh", 3 to "Developer") myImmuMap["Anupam"] = 5 // Update Anupam value from 1 to 5
Iterating over map entries via the map keys
You can use a for loop to iterate over a map. In this case we are iterating the map using the keys property, which contains all the keys present in the Map:val myImmuMap = mapOf<Int,String>(1 to "Anupam", 2 to "Singh", 3 to "Developer") for(key in myImmuMap.keys){ println(myImmuMap[key]) } // Output: // Anupam // Singh // Developer
Iterating over map values
We can also use a for loop to iterate over a map’s values, ignoring the map keys:val myImmuMap = mapOf<Int,String>(1 to "Anupam", 2 to "Singh", 3 to "Developer") for(value in myImmuMap.values){ println(value) } // Output: // Anupam // Singh // Developer
Other map functions and operations
Kotlin provides several useful functions and operations for working with maps. Some common ones include:
keys : This method retrieves a set, comprising all the keys present in the map.
values : The values function ensures retrieval of a collection, containing all the values stored in the map.
containsKey(key) : Determines whether a key exists in the map.
containsValue(value) : Checks whether a value exists in the map.
We have seen keys and values in the previous examples. Now let’s see the other methods in action.
Checking the existence of keys or values in the map
As we have mentioned, you can use the containsKey(key) function to check whether a specific key exists in the map, or the containsValue(value) function to determine whether a particular value is present in the map.val myImmuMap = mapOf<Int,String>(1 to "Anupam", 2 to "Singh", 3 to "Developer") // example of ***containsKey(key)*** println(myImmuMap.containsKey(2)) // exists so will print true println(myImmuMap.containsKey(4)) // not exists so will print false // Output: // true // false // example of ***containsValue(value)*** println(myImmuMap.***containsValue***("Ajay")) // not exists so print false println(myImmuMap.***containsValue***("Anupam")) // exists so print true // Output : // false // true
Working with Kotlin Set
Creating and manipulating sets in Kotlin
Creating a Kotlin Set is similar to other collections. You can use setOf() for an immutable set and mutableSetOf() for a mutable set. Here’s an example:// Immutable Set val intImmutableSet = setOf(1, 2, 3) for(element in intImmutableSet){ println(element) } // Output: // 1 // 2 // 3 // Mutable Set val intMutableSet = mutableSetOf(14, 24, 35) for(element in intMutableSet){ println(element) } // Output: // 14 // 24 // 35
Other useful Kotlin set operations and functions
Sets have unique characteristics that make them useful in certain scenarios. Common set operations include:
union() : Returns a new set that is the union of two sets.
intersect() : Returns a new set that is the intersection of two sets.
add(element) : A new element is added to enhance the set.
remove(element) : Removes an element from the set.
In the following example we show how to use the union() function:// Example of Union function val firstNum = setOf(1, 2, 3, 4,5) val secondNum = setOf(3, 4, 5,6,7,8,9) val finalUnionNums = firstNum.union(secondNum) println(finalUnionNums) // Output : // [1, 2, 3, 4, 5, 6, 7, 8, 9]
And here we have an example of intersect()// Example of Intersect function val fArray = arrayOf(1,2,3,4,5) val sArray = arrayOf(2,5,6,7) val iArray = fArray.intersect(sArray.toList()).toIntArray() println(Arrays.toString(iArray)) // Output: // [2, 5]
Iterating over Kotlin Set elements
Iterating through a set bears resemblance to iterating through a list. You can use a ‘for’ loop, or other iterable operations, to process each element.val intImmutableSet = setOf(1, 2, 3) for(element in intImmutableSet){ println(element) } // Output: // 1 // 2 // 3
Use cases and examples of sets in Kotlin
Sets are particularly useful when you need to maintain a collection of unique elements. For example:
Keep track of unique user IDs in a chat application.
Ensure that a shopping cart contains only distinct items.
Manage tags or categories without duplicates in a content management system.
Sets also simplify the process of checking for duplicates and ensuring data integrity.
FAQs
How do I filter strings from a Kotlin list?
To extract only strings, which can contain elements of any type, utilize the filterIsInstance() method. This method should be invoked on the kist, specifying the type T as String within the filterIsInstance() function.
The appropriate syntax for filtering only string elements within a list is:var myList: List<Any> = listOf(41, false, "Anupam", 0.4 ,"five", 8, 3) var filteredList = myList.filterIsInstance<String>() println("Original List : ${myList}") println("Filtered List : ${filteredList}") // Output : // Original List : [41, false, Anupam, 0.4, five, 8, 3] // Filtered List : [Anupam,five]
Executing filterIsInstance() will yield a list consisting solely of the String elements present within the original list, if any are found.
How do I define a list of lists in Kotlin?
The Kotlin list function listOf() is employed to generate an unchangeable list of elements. This function accepts multiple arguments and promptly furnishes a fresh list incorporating the provided arguments.val listOfLists = listOf( listOf(1, 2, 3), listOf("Anupam", "Singh", "Developer") ) print(listOfLists) Output: [[1, 2, 3], [Anupam, Singh, Developer]]
How do I filter only integers from a Kotlin list?
To extract only integers, which can contain elements of any type, you should utilize the filterIsInstance() method. This method should be invoked on the list, specifying the type T as Int within the filterIsInstance() function.
The appropriate syntax for filtering solely integer elements within a list is:var myList: List<Any> = listOf(5, false, "Anupam", 0.4 ,"five", 8, 3) var filteredList = myList.filterIsInstance<Int>() println("Original List : ${myList}") println("Filtered List : ${filteredList}") // Output : // Original List : [5, false, Anupam, 0.4, five, 8, 3] // Filtered List : [5, 8, 3]
Executing filterIsInstance() will yield a list consisting solely of the Int elements present within the original list, if any are found.
What are the different types of Kotlin Collections?
Kotlin’s official docs provide an overview of collection types in the Kotlin Standard Library, including sets, lists, and maps. For each collection type, there are two interfaces available: a read-only interface that allows accessing collection elements and provides some operations and then a mutable interface collections where you can modify the items. The most common collections are:
List
Set
Map (or dictionary)
How do I find out the length a Kotlin list?
To find out the length of a Kotlin list, you can use the size property. Here is an example:val myList = listOf(1, 2, 3, 4, 5) val length = myList.size println("The length of the list is $length")
Output:The length of the list is 5
What is List<*> in Kotlin?
In Kotlin, you can create a generic list with an unspecified type. When you use a generic list, you’re essentially saying, “I want a list of something, but I don’t care what type of things are in it”. This can be useful when you are writing generic code that can work with any type of list.fun printList(list: List<*>) { for (item in list) { println(item) } } val intList = listOf(1, 2, 3) val stringList = listOf("a", "b", "c") printList(intList) // This will print 1, 2, 3 printList(stringList) // This will print a, b, c
Can we use iterators to iterate a Koltin collection?
Yes, you can use iterators in Kotlin. In the previous examples we have seen how to iterate a Kotlin collection using for or forEach. In case you want to use iterators, here you can see an example of iterating a Kotlin list with an iterator.val myList = listOf("apple", "banana", "orange") val iterator = myList.iterator() while (iterator.hasNext()) { val value = iterator.next() println(value) }
In the example, we call iterator() on the list to get the iterator for the list. The while loop then uses hasNext() to check if there is another item in the list and next() to get the value of the current item.
0 notes
Text
Java Collections Framework: A Comprehensive Guide

The Java Collection Framework (JCF) is one of the most important features of the Java programming language. It provides a unified framework for representing and managing collections, enabling developers to work more efficiently with data structures. Whether you are a beginner or an experienced Java developer, understanding the Java collection system is important. This comprehensive guide will delve into the basic design and implementation of the Java compilation system, highlighting its importance in modern Java programming. The basics of the Java collections framework At its core, the Java collections in Java with Examples consist of interfaces and classes that define collections. These collections can contain objects and provide functions such as insertion, deletion, and traversal. The main features of JCF include List, Set, and Map. Lists are ordered collections of objects, aggregates are unordered collections without duplicate objects, and maps are key-value pairs. Significant interactions with classes in the Java collection system List Interface: Lists in JCF are implemented by classes like ArrayList and LinkedList. ArrayList provides dynamic arrays, allowing quick access to elements, while LinkedList uses a doubly linked list internally, making insertion and deletion faster Set interfaces: Represent classes such as sets, HashSet and TreeSet, and do not allow duplicate elements. HashSet uses hashing techniques for fast access, while TreeSet maintains objects in sorted order, enabling efficient retrieval. Map Interface: Maps are represented by HashMap and TreeMap. HashMap uses hashing to store key-value pairs and provides a constant-time display for basic processing. TreeMap, on the other hand, maintains elements in a sorted tree structure, enabling operations in logarithmic time. Advantages of Java Collections Framework The concurrent Collections in Java Framework offers several benefits to developers: Re-usability: Pre-implemented classes and interfaces let developers focus on solving specific problems without worrying about downstream data structures Interactivity: Collections in JCF can store object by object, encouraging interactivity and allowing developers to work with multiple data types. Performance: The system is designed to be efficient. The algorithm is implemented in such a way that it is efficient in terms of time and memory consumption. Scalability: JCF supports scalability, allowing developers to handle large amounts of data without worrying about memory limitations. Frequent use of information in the Java collections system Data Storage and Retrieval: Lists, sets, and maps are widely used to store and retrieve data efficiently. Lists are suitable for sorted collections, aggregates for unique elements, and maps for key-value pairs. Algorithm Implementation: Java Collections Framework can be used to implement many algorithms such as search and sort. This simplifies the coding process and reduces the possibility of error. Concurrent control: Classes like ConcurrentHashMap and CopyOnWriteArrayList provide concurrent access to collections, ensuring thread safety in multi-threaded applications. Best practices for Java collections systems with examples 1. List Interface (ArrayList):import java.util.ArrayList;import java.util.List; public class ListExample {public static void main(String args) {List list = new ArrayList(); // Adding elements to the list list.add("Java"); list.add("Python"); list.add("C++"); // Accessing elements using index System.out.println("Element at index 1: " + list.get(1)); // Iterating through the list System.out.println("List elements:"); for (String language : list) { System.out.println(language); } // Removing an element list.remove("Python"); System.out.println("List after removing 'Python': " + list); } } 2. Set Interface (HashSet) import java.util.HashSet;import java.util.Set; public class SetExample {public static void main(String args) {Set set = new HashSet(); // Adding elements to the set set.add("Apple"); set.add("Banana"); set.add("Orange"); // Iterating through the set System.out.println("Set elements:"); for (String fruit : set) { System.out.println(fruit); } // Checking if an element exists System.out.println("Contains 'Apple': " + set.contains("Apple")); // Removing an element set.remove("Banana"); System.out.println("Set after removing 'Banana': " + set); } 3. Map Interface (HashMap):import java.util.HashMap;import java.util.Map; public class MapExample {public static void main(String args) {Map map = new HashMap(); // Adding key-value pairs to the map map.put("Java", 1); map.put("Python", 2); map.put("C++", 3); // Iterating through the map System.out.println("Map elements:"); for (Map.Entry entry : map.entrySet()) { System.out.println(entry.getKey() + ": " + entry.getValue()); } // Checking if a key exists System.out.println("Contains key 'Java': " + map.containsKey("Java")); // Removing a key-value pair map.remove("Python"); System.out.println("Map after removing 'Python': " + map); } Conclusion: In Java programming, the Java collections tutorial framework stands as the cornerstone of efficient data manipulation. Its versatile interfaces and classes empower developers to create complex applications, handling data structures with ease. Understanding the nuances of different types of collections, their functionality, and best practices is important for enabling Java developers aiming to build high-performance, scalable, and error-free applications Java collection concepts has been optimized to enable developers to unlock the full programming capabilities of Java Read the full article
0 notes
Text
Do You Need Coding Skills for Data Science? A Complete Guide for Beginners

In recent years, data science has grown into one of the most in-demand fields across industries. Whether it's healthcare, finance, marketing, or technology, organizations rely on data-driven insights to make smarter decisions. If you're curious about stepping into the world of data science, one question probably comes to mind: Do I need to know how to code?
The short answer is yes—coding is an essential part of data science. But don’t worry, you don’t need to be a software engineer to succeed. Let’s break down why coding matters in data science, how it’s used in day-to-day tasks, which languages are most helpful, and how even beginners can get started.
Why Coding Matters in Data Science
Data science involves collecting, cleaning, analyzing, and interpreting data to uncover trends and insights. To do this effectively, you need to communicate with your data—and that’s where coding comes in. Coding lets you instruct a computer to perform specific tasks, such as filtering data, building models, or visualizing results.
Unlike manual data entry or spreadsheet formulas, coding offers flexibility, scalability, and efficiency. It allows data scientists to handle massive datasets, automate repetitive tasks, and experiment with different approaches—all while ensuring accuracy and consistency.
In short, coding is the tool that transforms raw data into valuable information.
What Programming Languages Are Used in Data Science?
Python and R are the most popular programming languages in the data science world. Each has its strengths, and both are beginner-friendly with large communities, open-source libraries, and tons of learning resources.
Python is widely used because of its simplicity and versatility. It supports powerful libraries such as:
Pandas for data manipulation
NumPy for numerical operations
Matplotlib and Seaborn for data visualization
Scikit-learn for machine learning
TensorFlow and PyTorch for deep learning
R, on the other hand, is favored in academia and among statisticians. It excels at statistical modeling and offers libraries like ggplot2 for beautiful visualizations and caret for machine learning workflows.
Some professionals also use SQL for querying databases, and Java or Scala for big data tools like Apache Spark. However, starting with Python or R is more than enough for most aspiring data scientists.
How Coding Is Used in Everyday Data Science Tasks
Coding isn’t just about writing complex algorithms—it’s used across every stage of a data science project. From preparing the data to presenting the final results, here’s how coding plays a role:
In the early stages, data scientists use code to clean messy data. This involves filling in missing values, removing duplicates, and converting data into usable formats. For example, if you're analyzing customer feedback, you might write code to remove stop words or standardize spelling across entries.
Next comes exploratory data analysis (EDA), which is all about uncovering patterns. With a few lines of code, you can generate charts, histograms, or heatmaps that reveal trends or anomalies. This helps shape the direction of your analysis.
Then there’s model building. Whether you're predicting customer churn or classifying images, you’ll use code to select features, train models, and evaluate performance. With libraries like Scikit-learn, even beginners can build basic machine learning models in under 50 lines of code.
Key Coding Tasks in Data Science Projects
After getting comfortable with the basics, you’ll use coding skills in more advanced and practical areas such as:
Data preprocessing and transformation
Building dashboards and reports
Running statistical tests
Developing and deploying predictive models
Automating data pipelines
These tasks require logical thinking, attention to detail, and creativity. Even though it may seem overwhelming at first, consistent practice will help you develop confidence and problem-solving skills.
Practical Tips to Start Learning Data Science Coding
You don’t need a computer science degree to learn how to code. In fact, many successful data scientists come from non-technical backgrounds. If you're just starting out, focus on these beginner-friendly steps:
Pick one language (preferably Python) and stick to it. Learn the basics of syntax, variables, loops, and functions.
Use free resources. Platforms like Kaggle, Coursera, and DataCamp offer hands-on tutorials designed for beginners.
Practice with real datasets. Try analyzing weather data, movie ratings, or sports statistics to make learning more engaging.
Build small projects. For example, create a program that predicts house prices or classifies types of flowers.
Join online communities. Platforms like Stack Overflow, Reddit’s r/datascience, and GitHub can provide support and feedback.
Learning to code is like learning a new language. It takes time and effort, but every bit of practice moves you closer to fluency.
Do All Data Science Roles Require Coding?
Not all roles in data science require deep coding expertise. For instance, data analysts may focus more on using tools like Excel, Tableau, or Power BI, which involve minimal coding. However, if you aim to become a data scientist or machine learning engineer, coding is a must-have skill.
There are also no-code and low-code platforms emerging in the industry, such as Alteryx and DataRobot, which make certain tasks easier for non-programmers. Still, understanding the underlying logic will give you a major advantage and help you work more effectively with data teams.
Conclusion
If you're serious about a career in data science, learning to code is not just helpful—it’s essential. Coding empowers you to explore, understand, and act on data in ways that static tools simply can't.
While the learning curve might seem steep at first, the journey is worth it. Start small, practice regularly, and stay curious. With time, you'll gain not only technical skills but also the ability to solve real-world problems through data.
Coding isn’t just a requirement in data science—it’s your most powerful tool for making sense of the digital world.
FAQ
Is coding hard to learn? Not necessarily. Python, for example, is known for its clean and readable syntax. With consistent practice, most beginners can pick up the basics within a few weeks.
Can I learn data science without coding? You can understand some concepts, but you’ll be limited in what you can actually do. To build models, automate tasks, or explore data deeply, coding is essential.
How much coding do I need to know before applying for a data science job? You should be comfortable with basic programming logic, data manipulation, and using libraries for visualization and machine learning. Building a few projects or participating in competitions on Kaggle can help you showcase your skills to employers.
0 notes
Text

How to remove duplicates from ArrayList? . . . . For more questions about Java https://bit.ly/3PyOJqD Check the above link
#array#arraylist#jdbc#hashcode#collection#comparator#comparable#blockingqueue#hashSet#treeSet#set#map#hashMap#iterator#listiterator#enumeration#list#collectionframework#ArrayList#thiskeyword#computersciencemajor#javatpoint
0 notes
Text
How to Implement HashMap in Java from Scratch

When working with Java, having a good understanding of data structures is essential. One such data structure is the HashMap, which allows efficient storage and retrieval of key-value pairs. In this article, we will learn how to implement a HashMap from scratch in Java, step by step. Understanding HashMap What is a HashMap? A HashMap is a data structure that stores key-value pairs and provides constant-time complexity for basic operations like insertion, deletion, and retrieval. It is part of the Java Collections Framework and is widely used in various applications. How does HashMap work? HashMap internally uses an array of linked lists to store the key-value pairs. Each element in the array is called a "bucket" and can contain multiple entries. The key is hashed to determine the index of the bucket. In case of hash collisions, where two or more keys hash to the same index, a linked list is used to handle collisions. Advantages of using HashMap - Fast access and retrieval of values based on keys. - Flexible size, as it adjusts dynamically based on the number of elements. - Support for null keys and values. - Efficient operations for inserting, deleting, and updating key-value pairs. Implementing HashMap Now let's walk through the steps to implement a HashMap from scratch in Java. Step 1: Creating the HashMap class We start by creating a new Java class named "HashMap" with the necessary attributes and methods. Our HashMap class will have a fixed size, defined by the number of buckets. Step 2: Defining the Entry class Next, we define a nested class called "Entry" that represents each key-value pair in the HashMap. The Entry class will have fields for the key, value, and a reference to the next Entry in case of collisions. Step 3: Implementing the put() method The put() method is used to insert a key-value pair into the HashMap. We first calculate the hash code of the key, then find the index of the corresponding bucket. If the bucket is empty, we create a new Entry and assign it to the bucket. If there is a collision, we append the new Entry to the linked list at that bucket. Step 4: Implementing the get() method The get() method retrieves the value associated with a given key from the HashMap. We calculate the hash code of the key, find the bucket, and iterate through the linked list to find the Entry with the matching key. If found, we return the corresponding value. Step 5: Implementing the remove() method The remove() method removes the key-value pair associated with a given key from the HashMap. We calculate the hash code of the key, find the bucket, and iterate through the linked list to find the Entry with the matching key. If found, we remove the Entry from the linked list. Testing the HashMap To ensure our implementation of HashMap is functioning correctly, we should write test cases to cover different scenarios. We can test the put(), get(), and remove() methods with various keys and values, including null values, and verify that the expected results are obtained. Conclusion In this article, we have learned how to implement a HashMap from scratch in Java. By understanding the internal workings and following the step-by-step approach, we can create our own custom HashMap. HashMaps provide efficient storage and retrieval of key-value pairs, making them valuable data structures in Java programming. FAQs What is the time complexity of HashMap operations? The time complexity of basic HashMap operations like put(), get(), and remove() is typically O(1) on average. However, in the case of hash collisions, the complexity can be O(n), where n is the number of elements in the linked list at a particular bucket. Can a HashMap contain duplicate keys? No, a HashMap cannot contain duplicate keys. If a duplicate key is inserted, the existing entry associated with that key will be replaced with the new entry. How does a HashMap handle null keys and values? A HashMap can have at most one null key and multiple null values. The null key is hashed to index 0, and null values can be stored in any bucket. Is HashMap thread-safe? No, the standard implementation of HashMap in Java is not thread-safe. If multiple threads concurrently access and modify a HashMap, it can lead to inconsistent results. To achieve thread-safety, you can use the ConcurrentHashMap class. How do HashMaps handle resizing? HashMaps have an initial capacity and load factor. When the number of elements exceeds the product of the capacity and load factor, the internal array is resized to accommodate more elements. This process involves rehashing all the existing entries and redistributing them to new buckets, which can be computationally expensive. Read the full article
0 notes
Text
Remove Duplicate Characters From a String In C#
Remove Duplicate Characters From a String In C#
Remove Duplicate Characters From a String In C# Console.Write(“Enter a String : “);string inputString = Console.ReadLine();string resultString = string.Empty;for (int i = 0; i < inputString.Length; i++){if (!resultString.Contains(inputString[i])){resultString += inputString[i];}}Console.WriteLine(resultString);Console.ReadKey(); Happy Programming!!! -Ravi Kumar Gupta.

View On WordPress
#.NET#c#Coding#java#Program#program in c#Programming#Remove Duplicate Characters From a String#Remove Duplicate Characters From a String In C#Technology
0 notes
Text
Write a program in java to demonstrate remove duplication from ArrayList to TreeSet?
Write a program in java to demonstrate remove duplication from ArrayList to TreeSet?
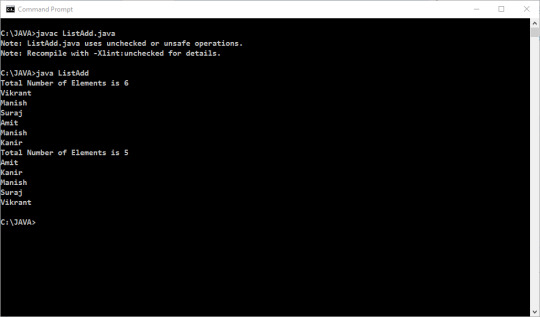
import java.util.*; public class ListAdd { public static void main(String arg[]) { Scanner in=new Scanner(System.in); ArrayList ls=new ArrayList(); TreeSet set=newTreeSet(); ls.add("Vikrant"); ls.add("Manish"); ls.add("Suraj"); ls.add(3,"Amit"); ls.add("Manish"); …
View On WordPress
1 note
·
View note
Text
Explain lists, sets, maps, and how to use them effectively.
Lists, Sets, and Maps:
Overview
Lists
Definition:
A list is an ordered collection of elements that can contain duplicates.
Characteristics:
Maintains the order of insertion. Allows duplicate values. Can store elements of any data type.
Usage Examples: Managing ordered data like a queue or a stack. Iterating over a collection of items in a specific order.
Common Operations:
Adding elements: list.append(value) Accessing elements: list[index] Removing elements: list.remove(value) Iterating: for item in list: Example: python Copy Edit fruits = [“apple”, “banana”, “apple”, “cherry”] fruits.append(“orange”) print(fruits) # Output: [‘apple’, ‘banana’, ‘apple’, ‘cherry’, ‘orange’]
2. Sets
Definition:
A set is an unordered collection of unique elements.
Characteristics:
Does not allow duplicates. Unordered, so the insertion order is not preserved.
Supports mathematical operations like union, intersection, and difference.
Usage Examples: Removing duplicates from a list.
Checking membership efficiently.
Performing set operations in mathematical contexts.
Common Operations:
Adding elements: set.add(value)
Removing elements: set.remove(value) Set union: set1.union(set2)
Set intersection: set1.intersection(set2) Set difference: set1.difference(set2)
Example:
python
unique_numbers = {1, 2, 3, 3, 4} unique_numbers.add(5) print(unique_numbers) # Output: {1, 2, 3, 4, 5}
3. Maps (Dictionaries)
Definition:
A map (or dictionary in Python) is a collection of key-value pairs where each key is unique.
Characteristics:
Keys must be unique and immutable.
Values can be mutable and of any data type. Provides fast lookups based on keys.
Usage Examples: Storing and retrieving data based on identifiers.
Implementing cache mechanisms. Grouping related information using key-value pairs.
Common Operations:
Adding key-value pairs: dict[key] = value
Accessing values: dict[key] Removing key-value pairs: del dict[key] Iterating over
keys and values:
for key, value in dict.items():
Example:
python
employee_details = {“name”: “John”, “age”: 30, “department”: “IT”} employee_details[“location”] = “New York” print(employee_details) # Output: {‘name’: ‘John’, ‘age’: 30, ‘department’: ‘IT’, ‘location’: ‘New York’}
When to Use Lists, Sets, and Maps
Effectively Data Structure Use When List — Order matters.
— You need to allow duplicates.
— Iterating in a specific sequence is required.
Set — Uniqueness is crucial. — Fast membership testing is needed. — Order is irrelevant.
Map — Fast key-based lookups are necessary. — Data is best represented as key-value pairs.
Best Practices Choose the right data structure:
Use a list when you need an ordered collection. Use a set when you want to eliminate duplicates or perform set operations.
Use a map when you need to associate keys with values for quick lookups.
Leverage built-in methods:
Python provides efficient methods for manipulating lists (sort, reverse), sets (union, difference), and maps (get, keys, values).
Optimize for performance:
Use sets for operations like membership testing (x in set) as they are faster than lists.
Use dictionaries for constant-time access to data by key.
Avoid unnecessary conversions: Use the native strengths of each data structure without repeatedly converting between them, which can impact performance.
With this knowledge, you can make informed choices about which data structure to use, improving both the clarity and efficiency of your code.
WEBSITE: https://www.ficusoft.in/core-java-training-in-chennai/
0 notes
Text
rough draft of the mission statement/rules of the server, to get some feedback and set some expectations before I start sending out discord invites!
Welcome to Androcraft! A semi-vanilla 1.18 Java SMP.
We have a few simple goals with this community:
Foster a positive and uplifting environment for people of all identities and walks of life, including and especially, male, male-aligned, and/or masculine persons.
Create a place to escape the stresses and anxieties of the outside world.
Have fun, and play some good old-fashioned minecraft!
In order to maintain those goals, these are our rules:
Respect others, their identities, and beliefs.
It is your duty to sort out personal issues with the parties in question, or to remove yourself from situations where problems may arise.
If your conduct in or outside of the server is found to be harmful, hateful, or egregious, you will be removed from the server.
Immediate removals will be made in the case of, but not limited to; racism, homophobia, transphobia, xenophobia, ableism, verbal or sexual harrassment, threats of violence, doxxing, …
No discourse, at all, ever.
Though it may be fun or cathartic to rant about certain topics such as transandrophobia, I ask that we keep this an environment focused around positivity and removal from topics that may induce stress, anxiety, sadness, anger, or frustration.
This includes both the minecraft and discord server, and no channels will be made for discussion of these topics, or any other vent or “heavy topics” channels. I hope you understand, and can find other communities to discuss these topics.
Keep things pg-13
This is a 16+ server. Please keep topics light and generally appropriate. Swearing is allowed.
Respect the server
You will not be judged on your skill level, but please do not construct things that are purposefully ugly, crass or obtrusive. You do not have to be an amazing builder, or a good one even, just create things earnestly.
Please keep your redstone contraptions and farms reasonable to avoid excessive amounts of lag. You may be asked to make modifications as we figure out what the limits are.
Respect other players. Ask when building near others. Griefing, stealing, using cheats, duplication glitches or hacks is obviously not allowed.
Keep spam and capslock to a minimum in chat.
8 notes
·
View notes